
1. 확률 분포의 정의
"확률분포(probability distribution)은 확률변수가 특정한 값을 가질 확률을 나타내는 함수를 의미한다."
확률변수는 아래 글을 참고하시고
확률변수(Random Variable)
확률변수의 정의 확률변수(random variable)란, 확률현상에 기인해 결과값이 확률적으로 정해지는 변수를 의미합니다. 확률현상이란 확률현상이란 어떤 결과들이 나올지는 알지만 가능한 결과들 중 어떤 결과가 나..
percept.tistory.com
확률분포는 ‘함수’를 의미하는데요. 함수란 mapping을 의미합니다. 즉, 함수란 집합의 임의의 한 원소를 다른 집합의 한 원소에 대응시키는 관계를 의미합니다. 즉, 확률분포란 확률변수가 특정 값을 가질 확률이 얼마나 되느냐를 나타내는 것입니다.
확률 분포는 확률 변수의 종류에 따라 이산확률분포와 연속확률분포로 나뉘는데요. 쉽게 말해 확률변수를 셀 수 있는지 없는지에 따라 나눈다고 생각하시면 됩니다.
독립항등분포(iid, independent and identically distributed)
두 개 이상의 확률변수를 고려할 때, 각 변수들이 통계적으로 독립(independent)이고, 동일한 확률분포를 가지고 있을때(identically distributed) 독립항등분포를 따른다고 하는데요. 실제로 독립항등분포라는 한글 쓰는 대신 iid라고 줄여서 부릅니다.
2-1. 이산확률분포
이산확률분포(discrete probability distribution)는 이산확률변수의 확률분포를 의미합니다. 여기서 이산확률변수는 확률변수가 가질 수 있는 값의 개수를 셀 수 있다는 의미입니다. 예를 들어, 확률변수 X를 주사위를 던져서 나오는 눈의 개수라고 하면 X는 1,2,3,4,5,6 여섯가지 경우를 가질 수 있습니다. 그리고 이 경우 확률변수가 가질 수 있는 값이 6개로 ‘셀 수 있는’ 경우 이므로 이산확률변수에 해당합니다.
2-2. 확률질량함수
확률질량함수(probatility mass function, pmf)는 이산확률변수에서 특정 값에 대한 확률을 나타내는 함수입니다.
즉 확률질량함수란 이산확률변수가 특정 값을 가질 확률을 의미합니다. 예를 들어 주사위를 던졌을 때 나오는 수를 X라고 하면 X가 1일 확률을 1/6이 된다는 것을 알 수 있습니다. 이를 수식을 나타내면 아래와 같습니다.
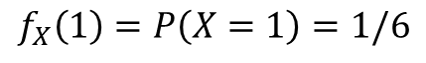
여기에서 fx(x)는 확률질량함수이며, fx(1)은 확률변수 X가 1일 때의 확률을 의미합니다. P(X=1)도 확률변수 X가 1일때의 확률을 의미합니다.
3-1. 연속확률분포
연속확률분포(continuous probability distribution)은 연속확률변수의 확률분포를 의미합니다. 여기서 연속확률변수는 확률변수가 가질 수 있는 값의 개수를 셀 수 없다는 의미입니다. 예를 들어, 임의로 선택한 사람의 키나 어느 지역의 연간 강수량 처럼 연속된 실수값을 확률변수 X로 둘 경우 이는 ‘셀 수 없는’ 경우에 해당합니다. 따라서 이 경우 확률변수 X는 연속확률변수에 해당한다고 할 수 있습니다.
3-2. 확률밀도함수
확률밀도함수(probability density function, pdf)는 연속확률변수가 특정 구간에 포함될 확률을 의미합니다.
확률밀도함수는 이산확률분포에서 확률 질량함수에 대응된다고 할 수 있습니다. 다만 확률밀도함수는 연속확률변수에 대응되기 때문에 특정값을 가질 확률은 0이 되므로 특정값을 가질 확률이 아닌 특정 구간에 포함된다고 표현합니다.
4. 누적분포함수
누적분포함수(cumulative distribution function, cdf)는 주어진 확률 변수가 특정 값보다 작거나 같은 확률을 나타내는 함수이다.
즉, 누적분포함수를 수식으로 나타내면 아래와 같습니다.

'통계학(Statistics) 기초' 카테고리의 다른 글
| 회귀모델에서 '회귀'란 무엇인가? (0) | 2020.05.01 |
|---|---|
| 통계학이란 무엇인가? (0) | 2020.05.01 |
| 이산확률분포 - 이항분포(Binomial Distribution), 베르누이 분포(Bernoulli Distribution) (0) | 2020.03.25 |
| 확률변수(Random Variable) (0) | 2020.03.25 |
| 평균(Mean)과 분산(Variance) (0) | 2020.03.25 |
